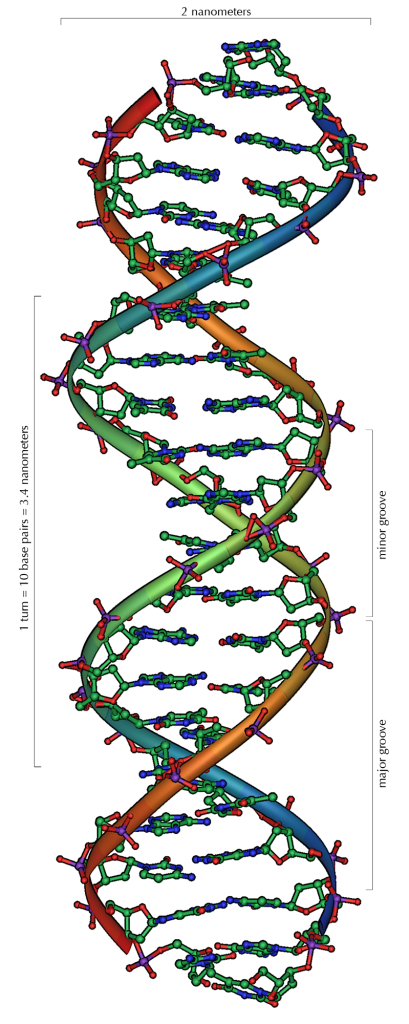
Immagine realizzata da Michael Ströck e rilasciata con licenza libera http://en.wikipedia.org/wiki/File:DNA_Overview.png
Il DNA è un polimero organico costituito da monomeri chiamati nucleotidi. Tutti i nucleotidi sono costituiti da tre componenti fondamentali: un gruppo fosfato, un deossiribosio e una base azotata. Il gruppo fosfato ed il ribosio si legano a formare lo scheletro della doppia elica, mentre i pioli sono costituiti da coppie di basi azotate. Le basi azotate che possono essere utilizzate nella formazione dei nucleotidi da incorporare nella molecola di DNA sono quattro: adenina (A), guanina(G), citosina (C) e timina (T).
L’ordine nella disposizione sequenziale dei nucleotidi costituisce l’informazione genetica.
Possiamo in effetti rappresentare questa informazione come una sequenza di lettere, o stringa di caratteri. Le stringhe di caratteri che otteniamo possono essere analizzate in vari modi e restituire informazioni con un significato biologico.
Il terminale
Iniziamo a familiarizzare con questa idea eseguendo dei semplici comandi su un file che contiene le sequenze nucleotidiche di alcuni geni.
Per prima cosa stampate a video il nome della directory in cui vi trovate: il comando pwd (print working directory) vi consente di farlo
Quindi spostatevi nella vostra home con il comando cd ~
Controllate utilizzando di nuovo pwd di avere eseguito il comando con successo e di essere in effetti nella home
A questo punto stampate a video la lista dei files contenuti nella vostra home con il comando ls (list)
Nella home dovreste aver trovato la cartella “esercitazione_bio”, stampate a video la lista dei files presenti in quella cartella digitando il comando ls esercitazione_bio (ricordavi che il TAB è un potentissimo strumento di aiuto!!!)
Ora spostatevi nella cartella dell’esercitazione utilizzando scrivendo cd eser e poi premendo TAB
Iniziamo a scoprire come sono fatti i files contenenti le sequenze di DNA stampandone a video il contenuto: cat sequenze.fasta
Se il file è molto lungo e quindi facciamo fatica a leggerlo possiamo iniziare stampando a video solo le prime righe, ad esempio digitando: head -n 20 sequenze.fasta
Un comando simile ci consente di stampare solo le ultime righe del file: tail -n 10 sequenze.fasta
Il file contenente le sequenze di DNA
Come avrete notato osservando con attenzione le vostre stampe a video, il file “sequenze” ha la seguente struttura: all’inizio della riga c’è un simbolo di maggiore seguito dal nome della sequenza; poi c’è un accapo; a partire dalla nuova riga c’è una lunga fila di lettere a, c, g, t senza spazi disposta su più righe che rappresenta appunto la sequenza di DNA. Sapreste dire quante sequenze di DNA distinte identificate da un nome ci sono in quel file?
Con il comando grep “>” sequenze.fasta stampate a video tutte le righe in cui è presente il simbolo “>” (grep è un comando molto utile con le sequenze di DNA, vale la pena approfondire)
E ora per sapere quante sono cosa fate, le contate con il dito dal video? mah no, potete lanciare due comandi in sequenza in questo modo: grep “>” sequenze.fasta | wc -l
Per salvare il risultato che avete ottenuto in un file, basta direzionare il risultato del vostro comando in un file grep “>” sequenze.fasta | wc -l > numero_sequenze.txt
Il nostro esercizio di oggi: utilizziamo le sequenze di DNA per capire cosa è successo ai nostri pazienti!
Cosa è successo
Nella città di New York si stanno verificando una serie di casi di tubercolosi. Alcuni malati vengono ricoverati nell’ospedale dove lavora un vostro amico medico, il quale tratta i pazienti con l’antibiotico Rifampicina. Mentre molti dei pazienti mostrano immediatamente segni di miglioramento alcuni non sembrano invece rispondere al farmaco. Per capire la ragione del problema e riuscire a curare i pazienti che peggiorano invece di migliorare il vostro amico contatta il servizio di microbiologia dell’ospedale e gli consegna i campioni prelevati da 5 pazienti che non rispondono all’antibiotico e da 5 pazienti che invece stanno rispondendo alle cure. Nel laboratorio di microbiologia i batteri che infettano ciascuno dei pazienti vengono coltivati e testati per vedere se sopravvivono all’antibiotico. In effetti i batteri che infettano i 5 pazienti che non rispondono alle cure proliferano in coltura nonostante la presenza dell’antibiotico, mentre quelli prelevati dai pazienti in via di miglioramento non sopravvivono in coltura in seguito alla somministrazione dell’antibiotico.
Da 2 colture batteriche (una di un paziente che risponde all’antibiotico e una di un paziente che non risponde) viene estratto il DNA e ne viene determinata la sequenza al fine di indagare meglio questo comportamento.
Le 2 sequenze ottenute vengono inviate proprio a voi, che sapete programmare, per vedere se da quelle stringhe di caratteri si riescano ad estrapolare delle informazioni utili. Le sequenze ottenute durante questa indagine si trovano in ciascuna delle vostre home nella cartella esercitazione_bio ed il nome dei file è DNAtubercolosi_sensibile e DNAtubercolosi_resistente (li dovreste aver visti già prima quando avete fatto ls all’interno di questa cartella)
Ripetete pure le operazioni fatte prima sul file sequenze.fasta e vedrete che questi due files hanno qualcosa di diverso, cosa?
Geni e Proteine
I geni sono porzioni di DNA che contengono tutte le informazioni necessarie per la produzione di una proteina. Hanno un sito di inizio e un sito di fine. Il sito di inizio è preceduto da un promotore. Il gene viene tradotto in proteina. La proteina esegue una o più funzioni.
Riusciamo ad associare qualche funzione alla stringa di caratteri che abbiamo ottenuto dal sequenziamento?
- Sapreste scrivere un programma che identifichi un promotore e l’inizio di un gene all’interno di una sequenza? Se ricordate le lezioni di biologia ci aspettiamo che un promotore batterico abbia una sequenza uguale a TTGACA 35 basi prima del sito di inizio della trascrizione ed una sequenza uguale a TATAAT 10 basi prima del sito di inizio della trascrizione. La struttura è quindi la seguente: TTGACA- 19 nucleotidi -TATAAT – 10 nucleotidi – sito di inizio trascrizione
- Ora passate al vostro programma i due file DNAtubercolosi_sensibile e DNAtubercolosi_resistente e per ciascuno stampate in un file le eventuali coordinate delle sequenze promotoriali e del sito di inizio del gene. Ci sono geni all’interno delle sequenze? Ci sono in tutte e due i files o solo in uno dei due?
Cosa hanno di diverso le sequenze dei batteri che infettano i pazienti che non rispondono alle cure?
- Sapreste scrivere un programma che confronti le due sequenze (DNAtubercolosi_sensibile e DNAtubercolosi_resistente) e restituisca una lista delle differenze e la posizione di queste differenze all’interno delle sequenze?
- Se avete trovato differenze, dove si trovano? All’interno di un gene, di una regione promotoriale o di una regione a cui non avete attribuito alcuna funzione?
(Solo per chi è superveloce ed ha finito di fare tutto in 2 ore
Incollate uno per volta il contenuto dei file DNAtubercolosi_sensibile e DNAtubercolosi_resistente nella finestra di input del programma che si trova a questo link otterrete la traduzione in proteina dei vostri eventuali geni di partenza. Scegliete l’opzione: translate in reading frame 2 on the direct strand.
Copiate su un file di testo la sequenza proteica ottenuta da ciascuno dei due files di partenza e salvateli come PROTEINAtubercolosi_sensibile e PROTEINAtubercolosi_resistente.
Potete ora far girare il vostro programma di confronto anche sui due files PROTEINAtubercolosi_sensibile e PROTEINAtubercolosi_resistente. Le differenze che avete visto fra le sequenze nucleotidiche si traducono anche in differenze fra le proteine o no? )
Cosa potrebbero significare queste differenze?
Con i dati che avete ottenuto proviamo a fare insieme una ipotesi su cosa sta succedendo. Ci ragioniamo insieme
Cosa c’è di vero in questa storia
La resistenza dei batteri agli antibiotici, un problema reale
E’ proprio utilizzando un metodo molto simile a quello che abbiamo descritto in questa esercitazione che si sono scoperte le basi molecolari di alcuni casi comuni di resistenza batterica agli antibiotici. Nel sito che vi ho lincato trovate una tabella che ne elenca alcuni divisi per tipologia.
La resistenza di Mycobacterium tuberculosis agli antibiotici e la nuova ondata di vittime della tubercolosi
Il caso che abbiamo esaminato noi oggi, è un caso reale di resistenza di Mycobacterium tuberculosis alla Rifampicina dovuto ad una mutazione puntiforme (cioè di una singola base del DNA) nel gene che codifica per una proteina fondamentale per la sopravvivenza del batterio: la subunità B della RNA Polimerasi. L’antibiotico Rifampicina si lega a questa proteina e ne blocca l’attività, così i batteri, senza una delle funzioni fondamentali per la sopravvivenza muoiono. Questa singola mutazione che abbiamo visto oggi (e ce ne sono altre note) impedisce alla Rifampicina di legarsi alla subunità B della RNA Polimerasi ma non impedisce alla RNA Polimerasi di svolgere la sua funzione, quindi i batteri continuano a proliferare anche in presenza dell’antibiotico.
Per approfondire sulla tubercolosi e per capire perchè nella mia storia ho scelto proprio New York, potete consultare la pagina di wikipedia dedicata a questa malattia.
La sequenza
La sequenza del gene per la “DNA-directed RNA polymerase subunit beta” di Mycobacterium tuberculosis H37Rv (un ceppo virulento sensibile alla Rifampicina) che avete utilizzato in questa esercitazione è la vera sequenza ottenuta da studi sperimentali e depositata nel database pubblico dell’NCBI. La differenza che avete trovato è una mutazione puntiforme realmente osservata in batteri che non rispondono all’antibiotico. Si tratta di una delle mutazioni sequenziate frequentemente nei soggetti resistenti ed è ampiamente studiata, è nota come mutazione in posizione 531. Il resido in posizione 531 è normalmente una serina, ma nei mutanti viene sostituita da un altro aminoacido. Il residuo 531 corrisponde al 450-esimo residuo amminoacidico della sequenza che vi ho fornito e la vostra mutazione scambia una serina con una prolina.
Cosa c’è di falso in questa storia
La sequenza “troppo perfetta”
Alcuni residui delle sequenza che vi ho fornito sono stati modificati per rendervi possibile la ricerca delle sequenze promotoriali tipiche dei batteri e del sito di inizio della traduzione. La sequenza originale ottenuta dall’NCBI è scaricabile a questo link, mentre a questo secondo link trovate la versione modificata (quella che avete utilizzato voi) in cui le basi cambiate sono indicate da lettere minuscole. Non tutti i geni batterici contengono tutte le sequenze canoniche che vi ho spiegato, a volte contengono una o più varianti di queste, rendendo più difficile l’identificazione del gene. Quello che avete imparato è tutto giusto e molto utile, diciamo solo che le analisi reali sono un po’ più complicate di così, ma intanto avete fatto il primo passo!